主页 > imtoken钱包官网 > 区块链百讲:知乎千赞解答详解挖矿过程
区块链百讲:知乎千赞解答详解挖矿过程

前几天整理了一下and的介绍。 看完后,我的朋友告诉我,我会尝试我的。 我默默地对他竖起了大拇指。 然后我觉得我应该做点什么来帮助他,所以我找到了更多关于比特币的信息。 挖币流程介绍,这篇文章很给力,想挖矿的同学慎重阅读~算法
另外,“区块链百讲”的目的是形成一个系统的区块链知识图谱,供大家查阅和了解区块链技术。 每天一一介绍,由浅入深。 欢迎在文末留言希望能有所了解,或者为文章指正错误,如果能投稿就更好了~服务器
1 挖矿过程
比特币挖矿的算法可以简单概括为对区块头进行两次sha256哈希运算。 如果得到的结果小于区块头指定的难度目标,则挖矿成功。微信
区块头的结构遵循网络
那么挖矿算法可以表示为iphone
block_header = version + previous_block_hash + merkle_root + time + target_bits + nonce for i in range(0, 2**32): if sha256(sha256(block_header)) < target_bits: break else: continue
简单回顾一下挖矿过程。学习
挖矿节点首先对交易进行验证,剔除有问题的交易,然后通过一组自定义的标准选择将哪些交易打包进区块,例如交易手续费占交易占用字节大小的比例超过有一定的门槛来判断,这样的交易才算盈利。 当然,节点也可以专门选择参与某笔交易,或者故意忽略某笔交易,每个挖矿节点都有很大的自由裁量权。 区块链

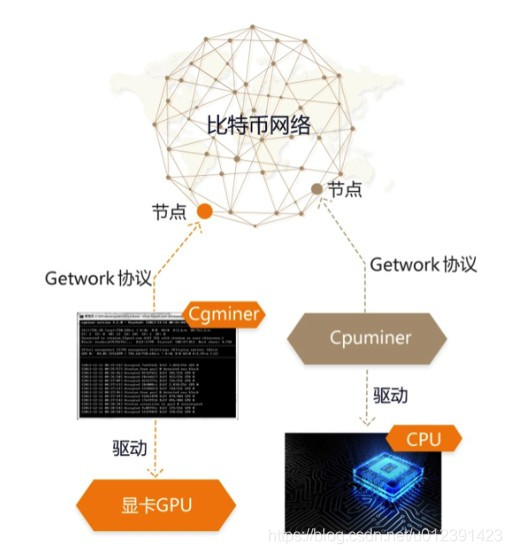
如果是通过矿池挖矿,矿池的服务器会对交易进行过滤,然后给每个参与的矿机分配一个独立的任务。 本次任务难度小于总挖矿难度,完成小难度计算,即确认涉及的工作量。 各个不同矿机的计算问题不再赘述。 当其中一台矿机成功挖矿后,其他矿机将根据工作量分配总收益。网站
交易数据经过筛选、按时间排序、成对哈希、逐层归约后,就可以通过这些交易计算出一棵默克尔树,并确定一个唯一的摘要,这就是默克尔树的根。编码
在默克尔树中,任何节点变化都会导致默克尔根发生变化。 通过这个值,可以用来验证区块中的交易数据是否被更改。 加密
然后依次获取挖矿所需的每个区块头信息。 区块头只有80字节,挖矿只需要对区块头进行操作即可。 交易数据通过默克尔树固定,不需要包含。 所谓区块链,其实就是通过区块头连接在一起的。 下面的示意图比较简单明了地解释了区块链和区块的组成。

比特币区块链图
区块头中的大部分信息在挖掘之前是固定的或可计算的。
版本号
取决于比特币客户端,暂时不会改变。 即使有变化,也会有比特币核心开发者协调升级策略,可以理解为静态常量。
前一个块的哈希摘要
一个哈希就足够了。 前一个块已经打包。
默克尔树的根
刚才已经得到了结果比特币挖矿的流程是什么,是根据本次交易包含的交易清单得到的。
时间
包裹被拿走的时间。 不需要很精确,几秒、几十秒就可以了。
难度目标
参考最近两周生成区块的平均生成时间。 如果两周内平均10分钟产生一个区块,那么两周将产生2016个区块。 软件会计算出最新的2016个区块的生成时间,然后进行比较,并相应调整难度,使得下一个区块的生成时间预计保持在10分钟左右。 由于最后 2016 个区块已经确认,这个数字也得到确认。
随机数 nonce
这就是挖矿的目标。 这是一个 32 位数字。

随机数可以变化,必须尝试从 0 到最大值 2^32。 直到出现最后一个哈希结果,其编号低于难度目标值。 但是以今天的计算机计算能力,一台矿机可以在不到一秒的时间内计算出所有的变化,所以需要改变区块内部的造币交易中的附带消息,让merkle根也发生变化。 , 从而有更多的可能性找到符合要求的 nonce。
合格区块条件如下:
SHA256D(Blockherder) < F(nBits)
其中SHA256D(Blockherder)为挖矿结果,F(nBits)为难度对应的目标值,均为256位,均视为大整数,直接比较大小判断是否满足难度要求。
为了节省区块链存储空间,将256位的目标值通过一定的变换和无损压缩存储在32位的nBits字段中。 具体转换方法是拆分使用4个字节的nBits。 第一个字节表示右移的位数,用V1表示,后3个字节记录数值,用V3表示,则:
F(nBits)=V_3 * 2^(8*(V_1-3) )
另外,难度有一个最小限制,也就是说F(nBits)有一个最大值,比特币的最小难度值为nBits=0x1d00ffff,对应的最大目标值为:
0x00000000FFFF0000000000000000000000000000000000000000000000000000
因此,挖矿可以比作抛硬币。 例如,有256枚硬币,给定的数字是1、2、3……256。 每进行一次哈希运算,就如同抛硬币一样。 同时抛出 256 个硬币。 所有编号在 n 之前的硬币都是正面朝上的。
在挖矿中,第一笔交易是硬币创造交易。 创建交易可以附带一条文本消息,可用于提供更多随机数。 就像中本聪挖出创世块时植入的信息一样。
泰晤士报 03/Jan/2009 财政大臣即将对银行进行第二次救助
2 算法验证
讲解完基本原理后,我们开始用实际数据来验证算法。我们以区块277316为例,其信息来源于网站
之所以选择这个区块,是参考了《精通比特币》一书中的介绍。 介绍这部分内容时,中文社区翻译与本书英文原版存在出入,作者Antonopoulos未做完整计算; 有一个重点没有提到,就是字节序的问题,相信很多人可能会踩到这个坑。 这里还原的细节可以帮助读者充分理解书中介绍工作量证明的算法部分。
来自比特币区块 277316 的信息
比特币区块哈希值 277316
3 算法演示
下面对具体的校验算法进行说明。
第一步,准备数据,转换时间
2 (版本号的十进制)0000000000000002a7bbd25a417c0374cc55261021e8a9ca74442b01284f0569 (前一区块hash值的16进制)c91c008c26e50763e9f548bb8b2fc323735f73577effbc55502c51eb4cc7cf2e (merkle root的16进制)2013-12-27 23:11:54 (utc时间) 419668748 (难度目标的十进制) 924591752 (随机数的十进制)
要转换时间,请记住,它必须转换为 utc 时间戳。 这里有陷阱,所以要小心。 算法本身并不难,难的是你需要正确准备好所有的数据。
>>> import datetime
>>> from datetime import timezone
>>> datetime.datetime.strptime('2013-12-27 23:11:54', '%Y-%m-%d %H:%M:%S').replace(tzinfo=timezone.utc).timestamp()
1388185914.0
第二步,全部转为十六进制
00000002 0000000000000002a7bbd25a417c0374cc55261021e8a9ca74442b01284f0569c91c008c26e50763e9f548bb8b2fc323735f73577effbc55502c51eb4cc7cf2e 52be093a 1903a30c371c2688

第三步,大端转小端
这一步的发现难度极大,多方查询和尝试,大坑大坑,切记! 发明者中本聪可能为了让机器计算速度更快,将编码方式改得更接近机器小端。
02000000 69054f28012b4474caa9e821102655cc74037c415ad2bba70200000000000000 2ecfc74ceb512c5055bcff7e57735f7323c32f8bbb48f5e96307e5268c001cc9 3a09be52 0ca30319 88261c37
还是那句话,算法不难,最难的是自己检查计算的过程,要把隐藏的知识都挖出来。 在中文资料中,很少有人查过全文,真正了解过查的过程后,你会发现比特币的算法真的不难。
第四步拼接字符串,开始验证
import binascii from hashlib import sha256 as sk = '0200000069054f28012b4474caa9e821102655cc74037c415ad2bba702000000000000002ecfc74ceb512c5055bcff7e57735f7323c32f8bbb48f5e96307e5268c001cc93a09be520ca3031988261c37 'hk = binascii.unhexlify(k)res = binascii.hexlify(s(s(hk).digest()).digest()[::-1])

为什么在代码中又转换了顺序? 也是因为字节序的问题,我们在日常使用和网站展示中使用的是big-endian顺序,所以需要进行转换。
最后得到的结果是
0000000000000001b6b9a13b095e96db41c4a928b97ef2d944a9b31b2cc7bdc4
在十六进制下,最前面有15个0,然后是1。 为了拿到这个号码,我花了将近一个星期的时间。 我开始学习椭圆曲线加密算法,然后阅读各种原始资料。 也下载了难的源码,搜了论坛。 看着眼前一堆0,感觉胜利的曙光就要来临了。
别着急,我们还要验证最后一步,是否满足难度指标。 当然够了,因为我们是在验证结果,但是如果是在正向计算的挖矿过程中,就必须验证。
难度目标对应的数字为
0x03a30c*0x0100**(0x19-0x03) = 0000000000000003a30c00000000000000000000000000000000000000000000
在十六进制下,第一个是15个0,然后是3个。
计算结果小于难度目标,满足要求。 那么这个结果一定就是网站公布的数字。
正确的散列值
挖矿的时候,nonce随机数是未知的,需要从0到2^32进行测试,但是这个数字其实并不大,只有4294967296,以目前矿机动辄14T每秒的算力,确实不用一秒钟让所有计算都达到上限。 如上所述,在这种情况下,需要使用造币交易中的附带信息,额外的字符串成为额外的随机数。
让我们解释一下这个结果意味着什么。 2013年底产生这个区块,需要8T/s算力的设备,即每秒8*10^15次暴力验证,连续工作10分钟。 这在2018年还真不是什么大事,一台矿机,两三块砖头大不了多少,算力14T/s比特币挖矿的流程是什么,一个人挖6、7分钟就够了。 但当时8T是全网算力的千分之一,需要数百台当时最好的矿机协同工作。 而这个计算如果使用普通台式电脑,则需要26年。 如果用2018年最好的手机iphoneX,每秒70次计算,需要四百万年。
通过以上算法,我们完整的回顾了比特币区块链的工作量证明算法。 如果你已经完全理清了思路,你可以手动实现自己的挖矿程序,或者尝试设计一些新的区域。 区块链产品。 我们希望底层能看懂最常见的技术,但底层的逻辑其实并不难。
然而,比特币中的技术远不止挖矿算法、加密算法、Script智能合约、各种协议、各种网络、交易验证,每一种都充满了魔力。 深度和广度。 不管比特币是什么,它会是什么样子,但随着比特币作为区块链技术的第一个大规模应用,它已经传播开来。 整个系统的严谨性和逻辑复杂性确实令人着迷。
4 还有一件事...
创世块也可以通过上述方法验证,好奇的朋友可以试试。 虽然后来在客户端硬编码了创世块,但还是被挖出来了。
暗示:
挖矿过程说完了,你明白了吗? 感觉可以试试挖~